
Amazon Redshift 用 Amazon Q 生成 SQL が一般提供開始したので試してみました!
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
AWS事業本部コンサルティング部の石川です。昨年のre:Invent2023 で発表された Amazon Redshift 用 Amazon Q 生成 SQL が一般提供開始されました。東京リージョンでもサービス提供されましたので、実際に動作を確認しながら解説します。
Amazon Q generative SQL for Amazon Redshift とは
Amazon Redshiftのクエリエディタ(Query Editor V2)からAmazon Qによって、ユーザーは自然言語でデータの問い合わせができるようになりました。この機能を使用すると、抽出したい情報を自然言語で表現するだけで、Amazon Qが適切なSQLクエリを自動生成します。これにより、クエリ作成の手間が大幅に軽減され、ユーザーの生産性が向上します。
新機能の有効化
Amazon Q generative SQL for Amazon Redshiftを有効化するには、Query Editor V2の画面左下にある設定アイコン(歯車アイコン)をクリックして、「Q Generative SQL settings」 を選択します。
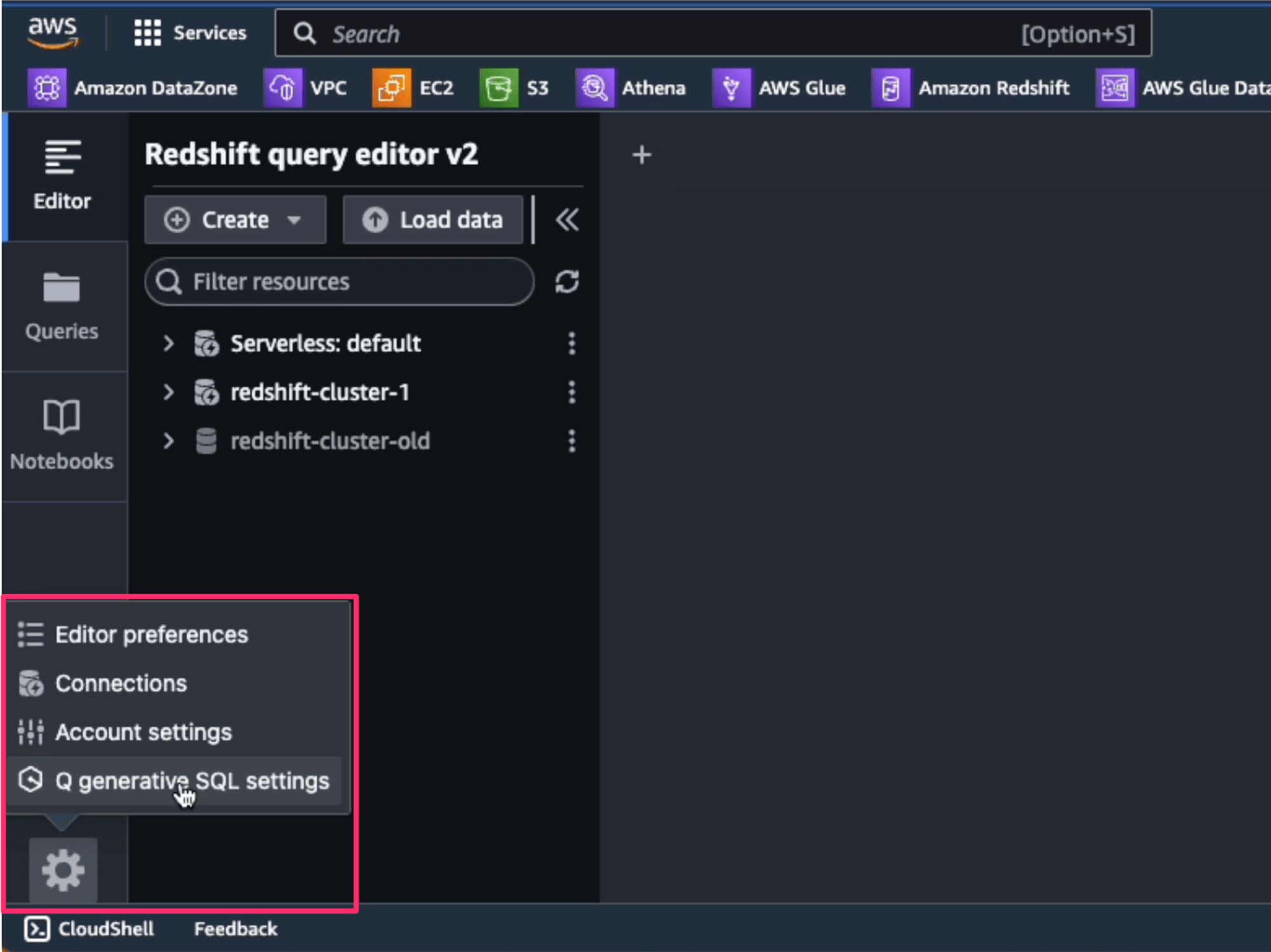
するとダイアログが表示されますので、「Q Generative SQL」 にチェックを入れて、[Save]ボタンを押すと設定完了です。
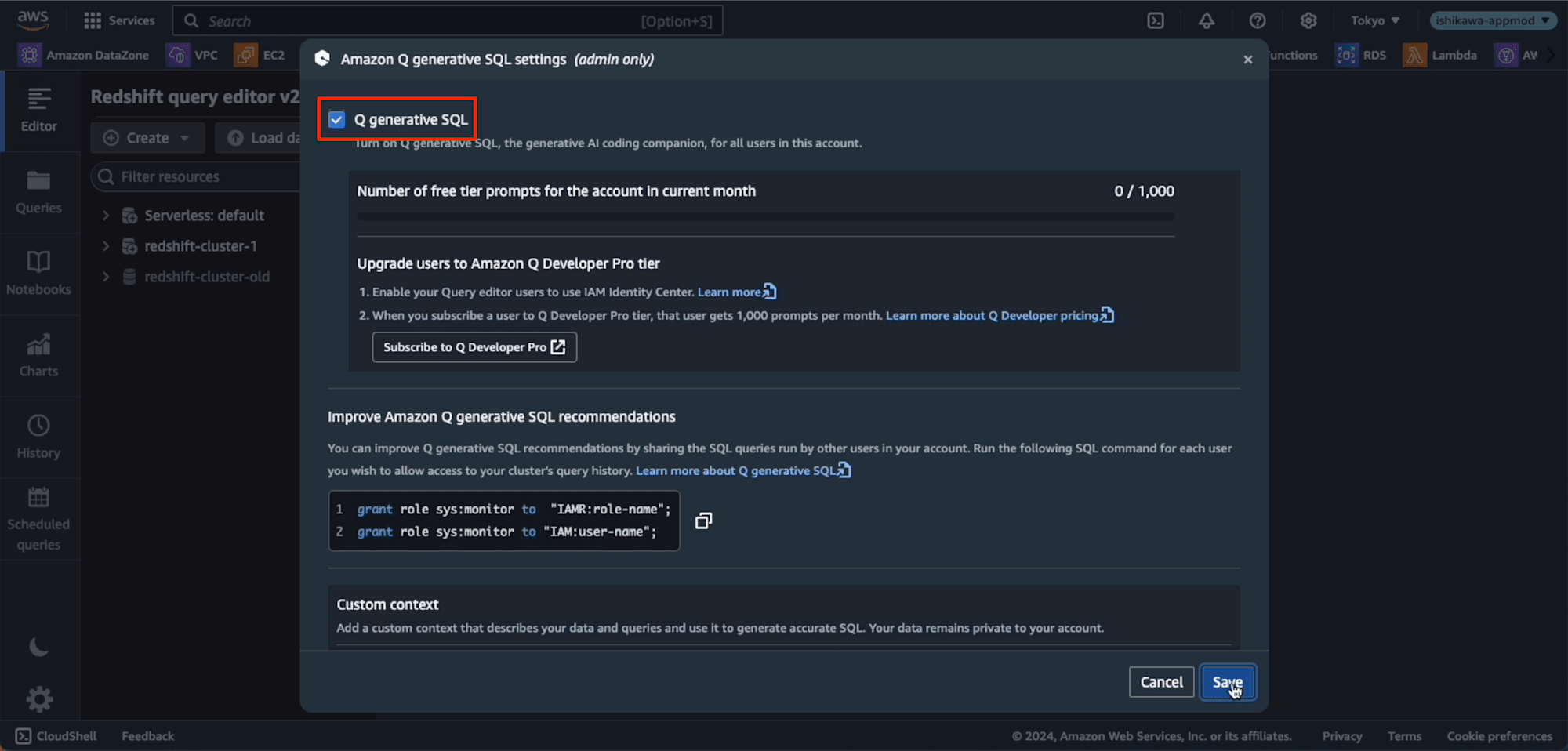
なお、上記の画面に「Number of free tier prompts for the account in current month 0/1000」とあるように、1ヶ月間1000プロンプトまで無料です。
Notebook の使い方
Amazon Q generative SQL for Amazon Redshiftは、Notebook で利用します。まずは、Notebookの使い方を簡単に解説します。(Notebookとは、Jupyter notebook の Notebook のようなものです。)
Notebookは、[+]ボタンを押して、Notebookを選択します。
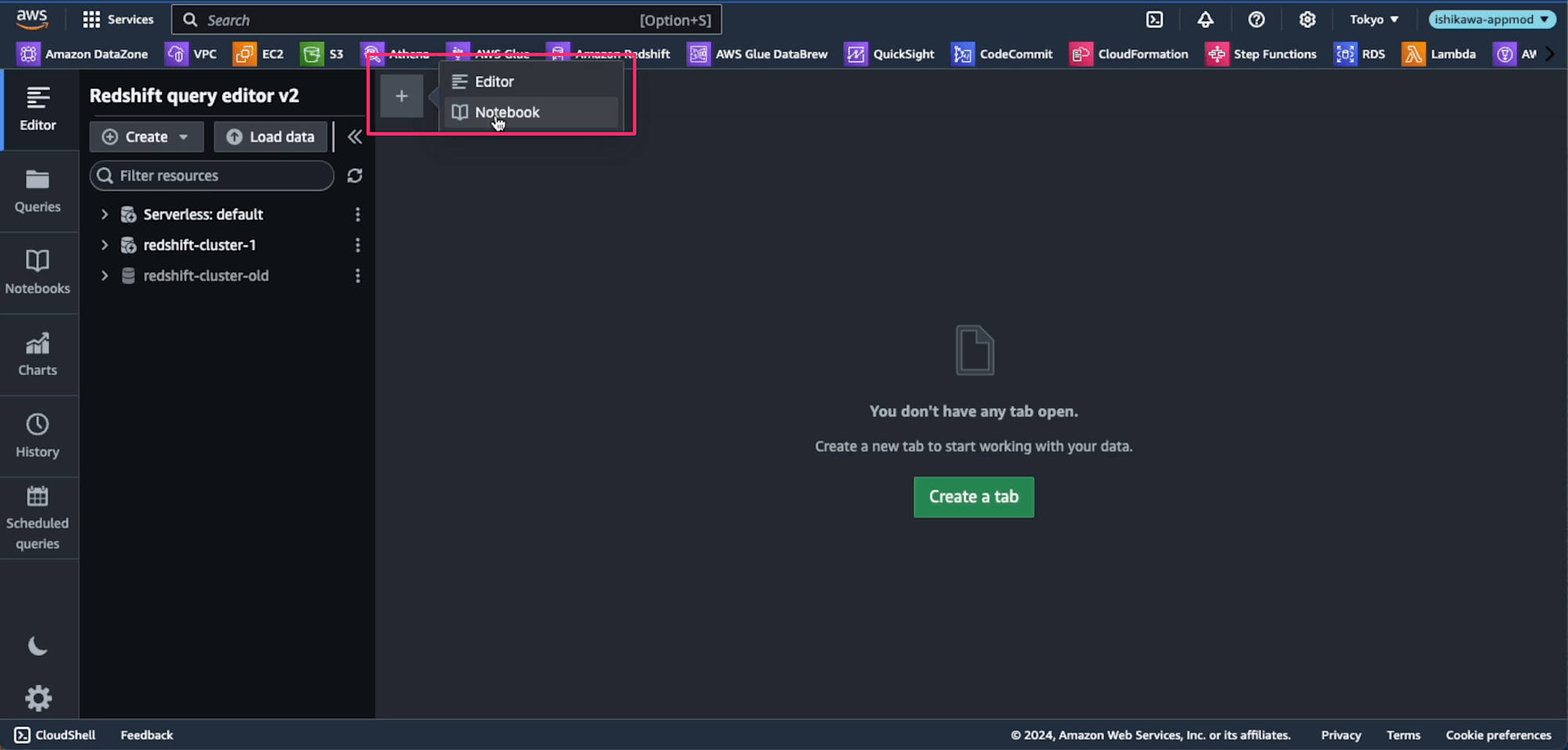
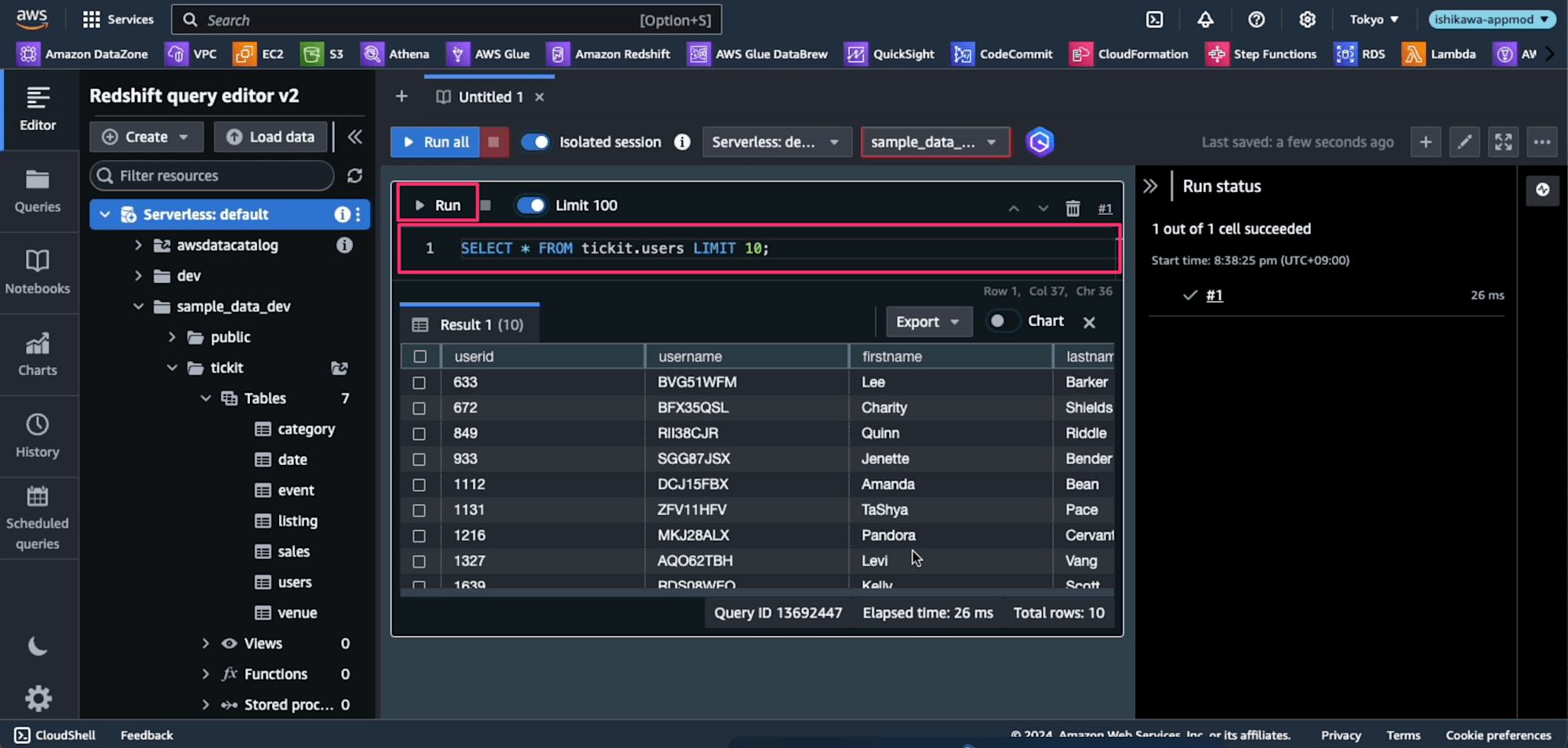
Notebookが表示されたら、SQLを入力して、上の[Run]を押すとクエリが実行します。
Amazon Q generative SQL for Amazon Redshiftを試す!
この機能は、上のAmazon Qアイコンをクリックすると、Notebookの右にウインドが表示されます。これがAmazon Q generative SQL の画面です。
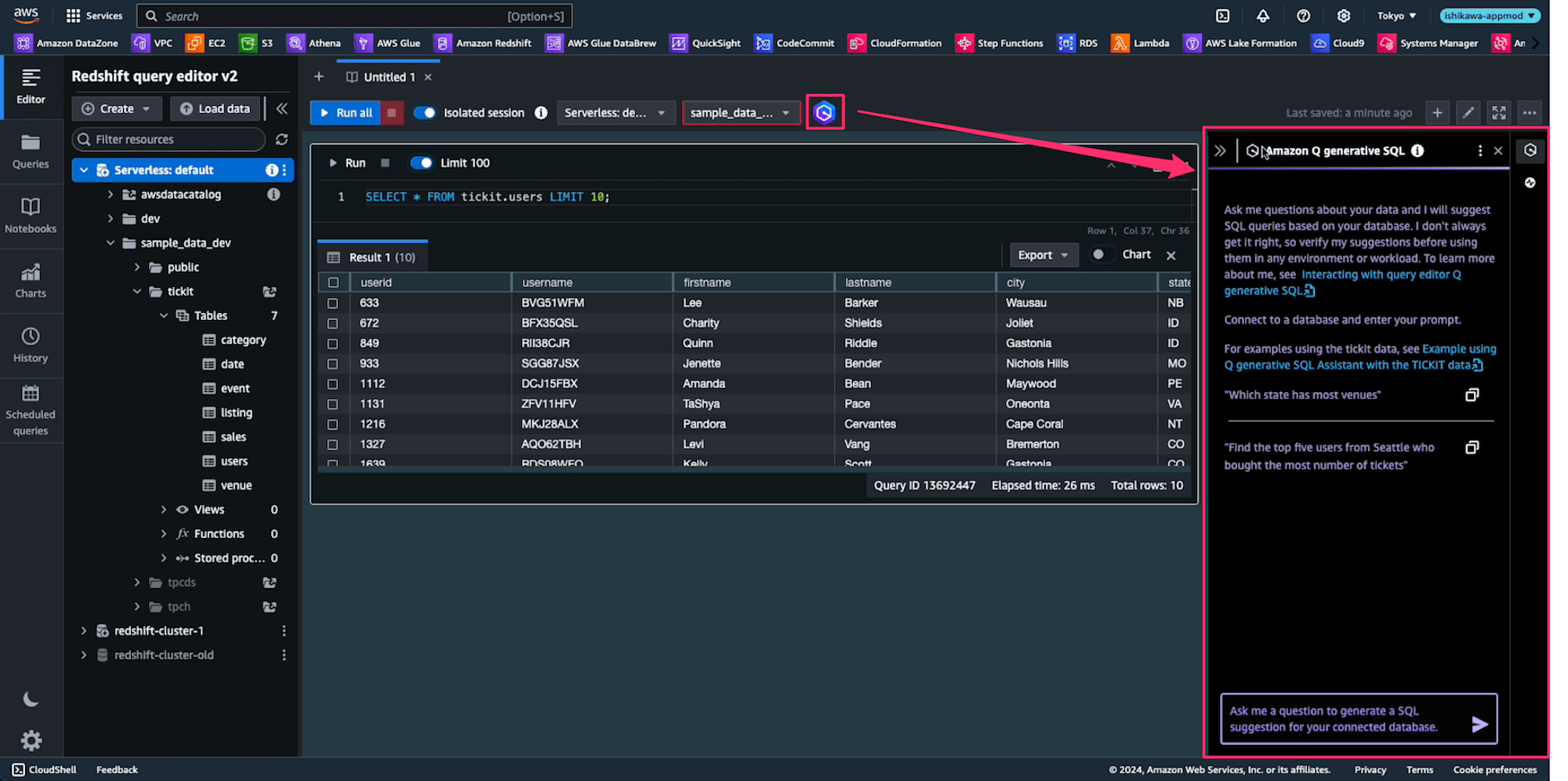
Notebookの右のウインドの中に書かれていることは、以下のとおりです。
Ask me questions about your data and I will suggest SQL queries based on your database.
I don't always get it right, so verify my suggestions before using them in any environment or workload.
To learn more about me, see Interacting with query editor Q generative SQL
Connect to a database and enter your prompt.
For examples using the tickit data, see Example using Q generative SQL Assistant with the TICKIT data
"Which state has most venues"
----------------------------------------------------------------------------
"Find the top five users from Seattle who bought the most number of tickets"
データについて質問していただければ、データベースに基づいて SQL クエリを提案します。
常に正しいとは限らないので、環境やワークロードで使用する前に、提案を確認してください。
詳細については、Query editor Q Generative SQL の操作を参照してください。
データベースに接続してプロンプトを入力します。
tickit データの使用例については、TICKIT データで Q Generative SQL アシスタントを使用する例を参照してください。「どの州に最も多くの会場があるか」
「シアトルで最も多くのチケットを購入した上位 5 人のユーザーを見つける」
今回の検証用のデータは、Amazon Redshift Serverless にデフォルトで入っている sample_data_dev データベースの tickit スキーマのデータを使用します。上記を見た感じ、「tickit データの使用例については、...」とあるように tickit スキーマのデータで分析しようというのが伝わってるかのようです。
プロンプトのサンプルが表示されているのでその通り実行したいと思います。
プロンプト: "Which state has most venues"
一番下の紫の枠に、プロンプトに"Which state has most venues"を入力して、[>]アイコンをクリックします。すると、上にプロンプトと期待通りのSQLが自動生成されました。
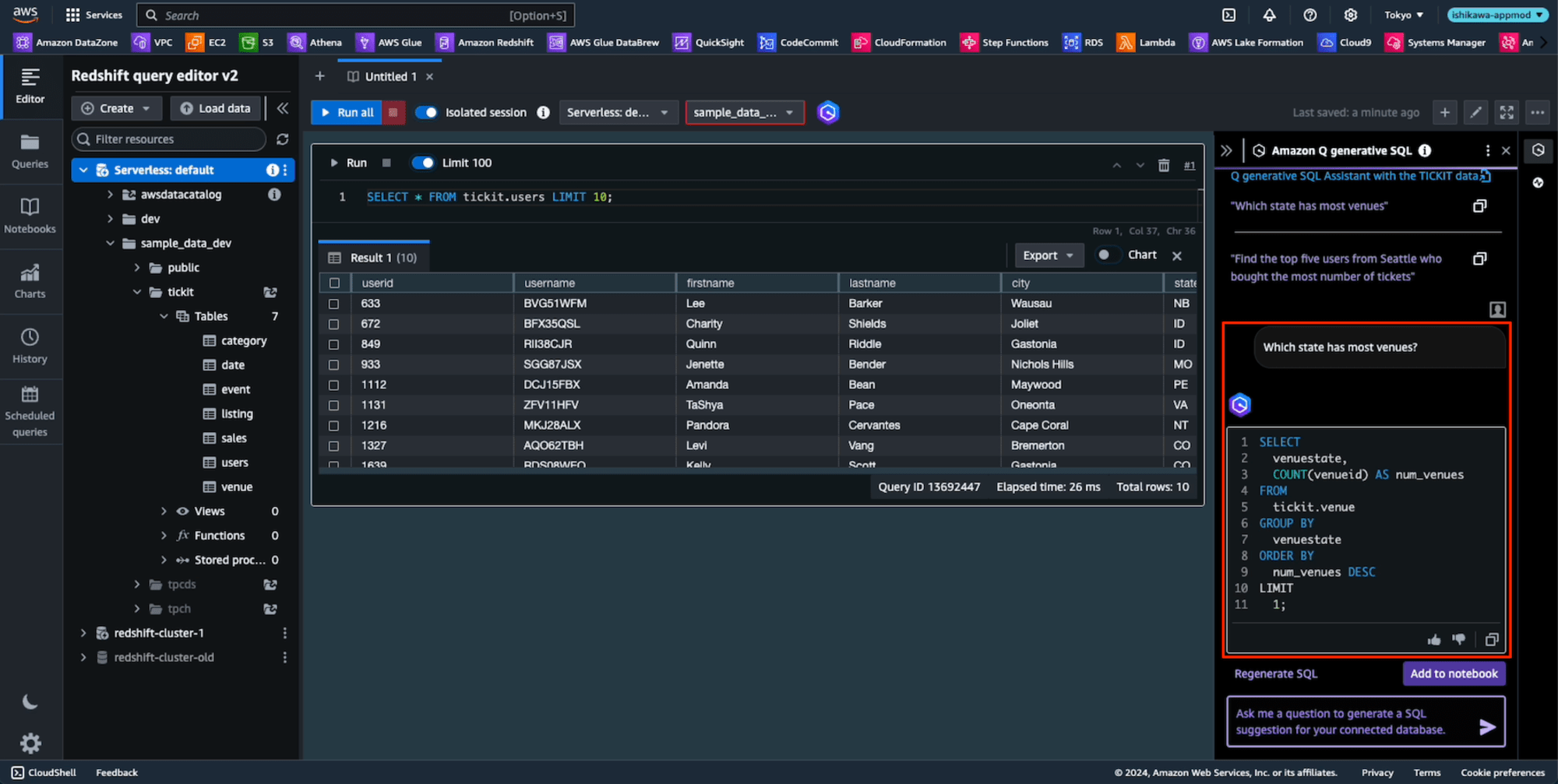
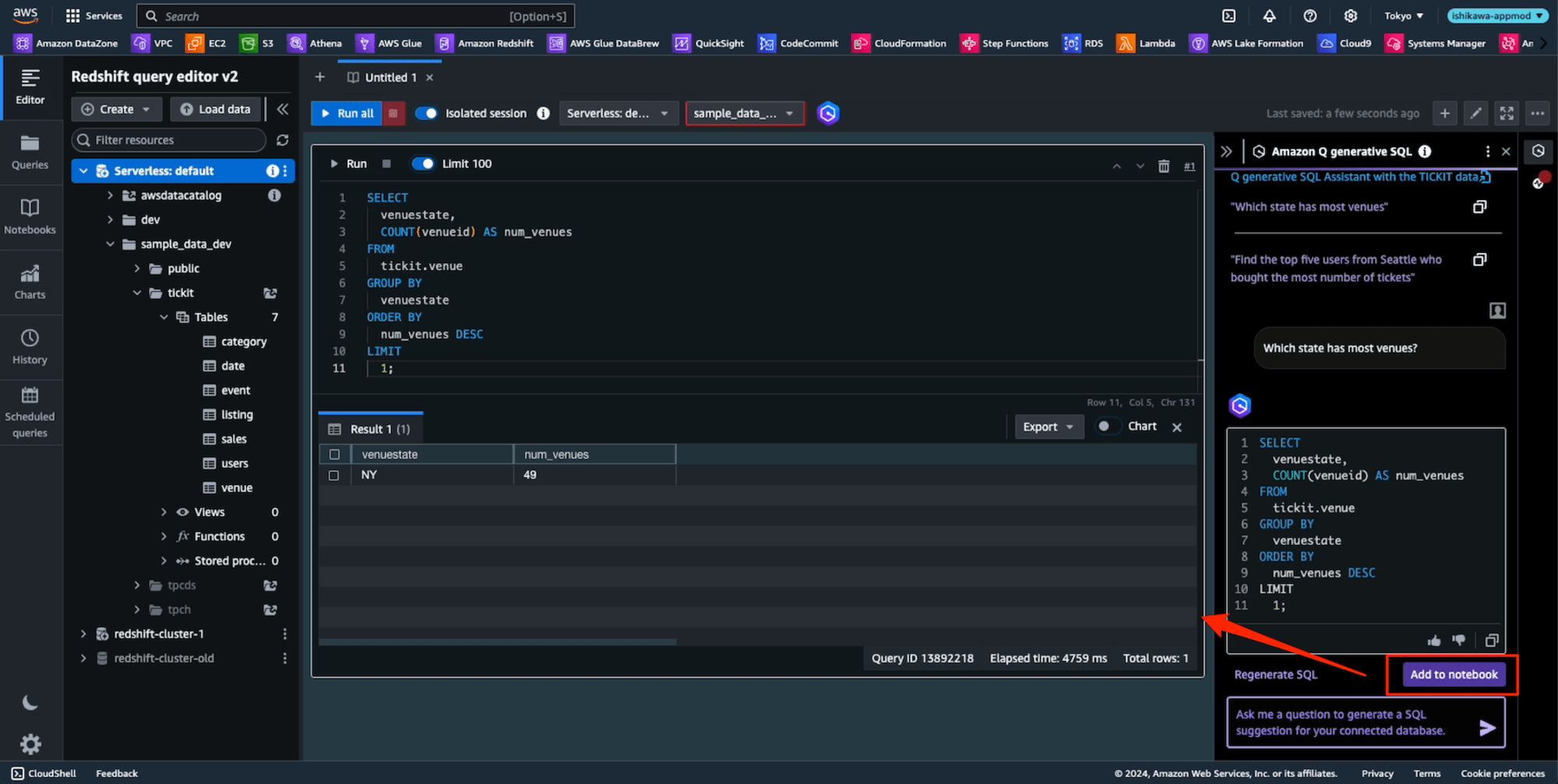
[Add to notebook]ボタンを押すと、左のNotebookにプロンプトと生成されたSQLが追加されます。ここで[Run]ボタンを押すと実行されます。
プロンプト: "Find the top five users from Seattle who bought the most number of tickets"
先程よりも複雑なプロンプト"Find the top five users from Seattle who bought the most number of tickets"を試しますが、期待したSQLがあっという間に生成されます。
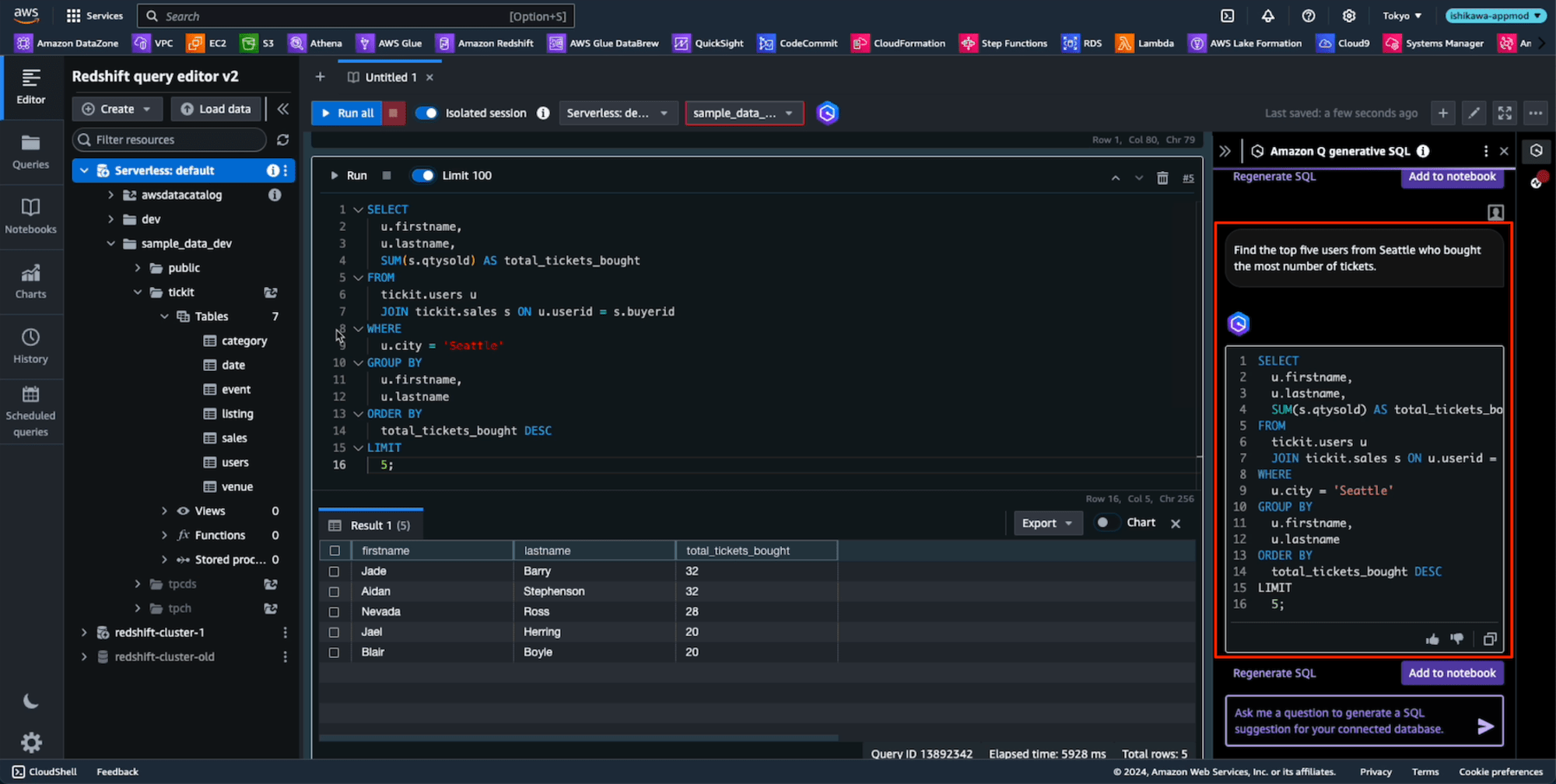
[Add to notebook]ボタンを押しプロンプトと生成されたSQLが追加、[Run]ボタンを押すと実行されます。
Amazon Qは日本語に対応していないはずですが、しれっと、Amazon Qに日本語プロンプトを入力して、いい感じに生成できているブログを思い出しました。
では、しれっと、私も日本語プロンプトを試してみます。
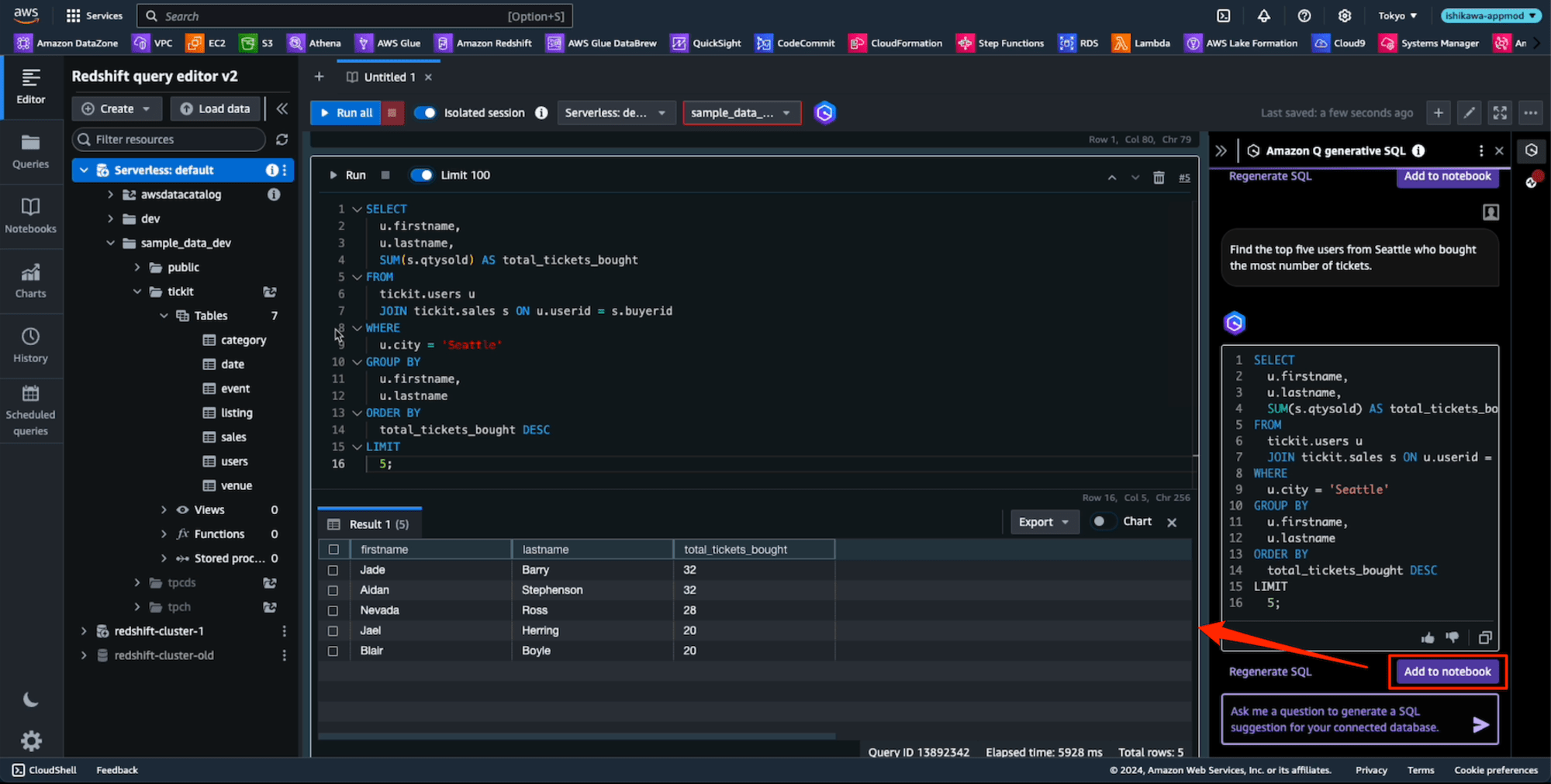
プロンプト: 「どの州に最も多くの会場があるか?」
あれ、日本語でいい感じにSQLを生成してる。
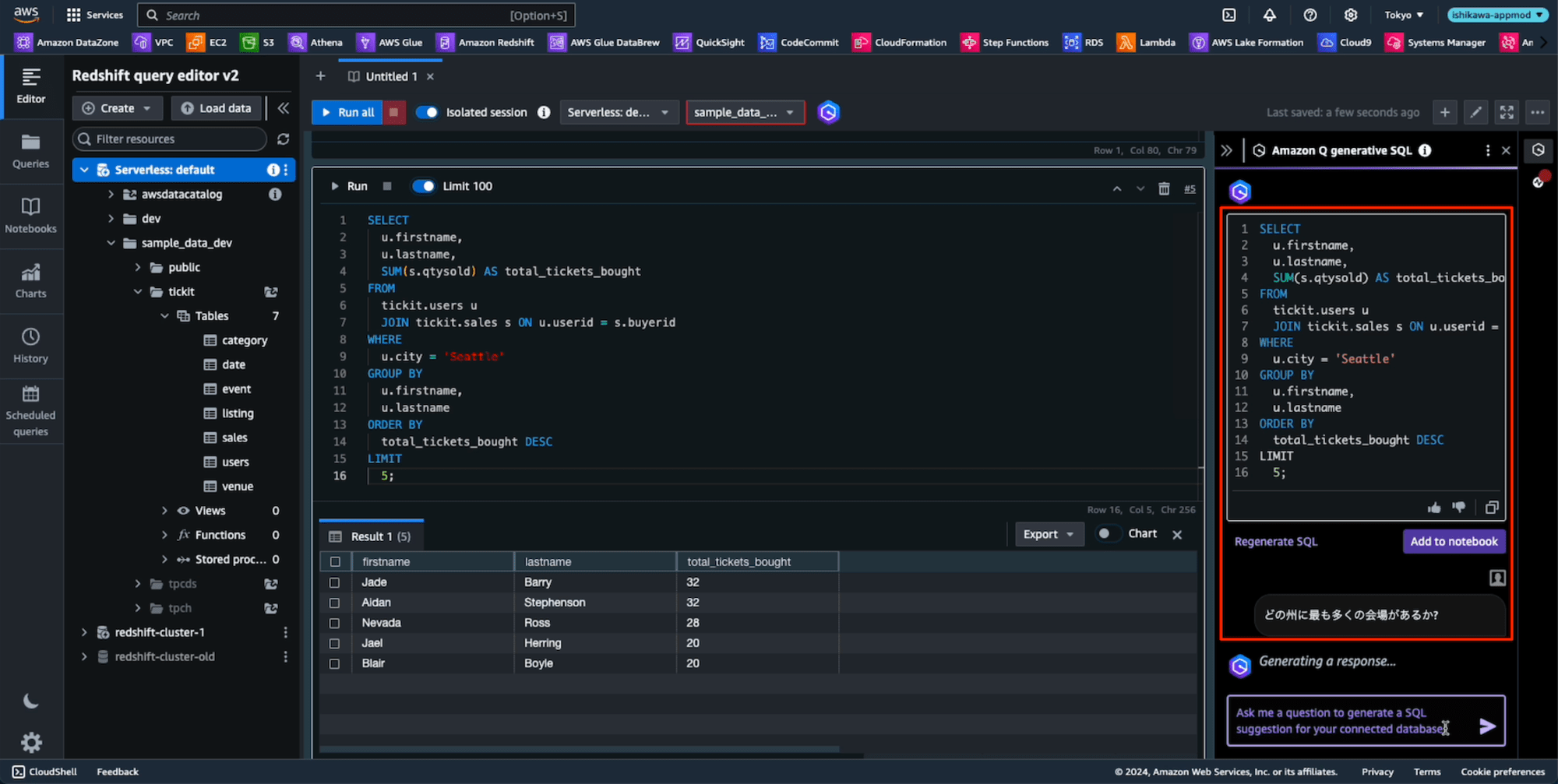
プロンプト: 「シアトルで最も多くのチケットを購入した上位 5 人のユーザーを見つける」
長めのプロンプトで、テーブル名と一致しない日本語プロンプトは、さすがに無理だろう、、、、、、って、いい感じにSQLを生成してる。
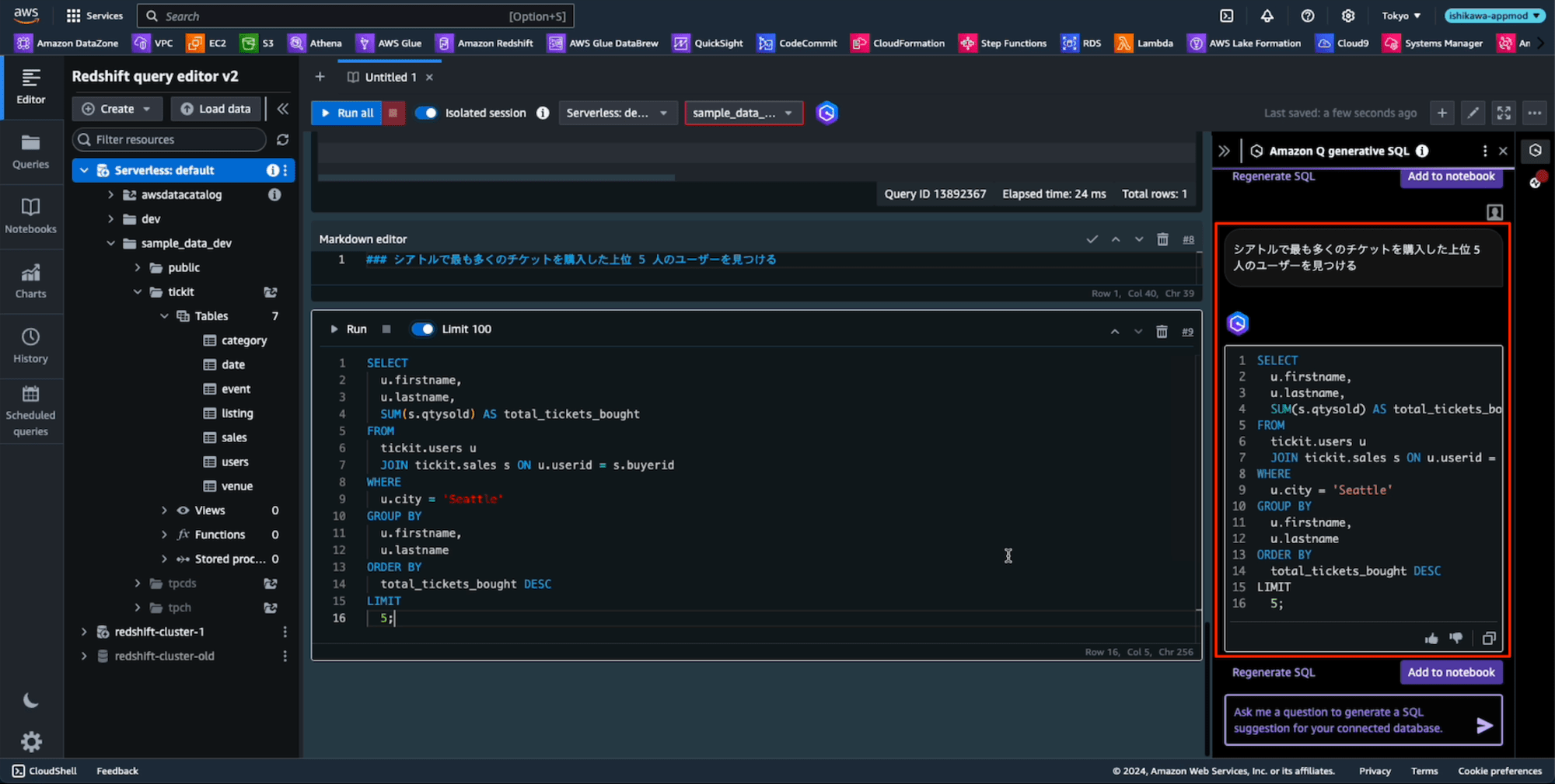
英語はもちろん、日本語でもベストエフォートでプロンプトからSQLが生成できるようです。
最後に
実は初回のSQL生成は、30秒ほど待たされましたが、それ以降は数秒で生成されました。恐らく、テーブルやカラム、それらのコメント、外部キーとプライマリキーの定義などのメタデータや実際のデータも一部スキャンして、SQLの生成に必要となるコンテキスト情報を収集しているのではと予想しました。これは Amazon DataZone の新しい生成 AIベースの新機能「AIリコメンデーション」を試してみる!を検証した際にも同じ印象を受けました。
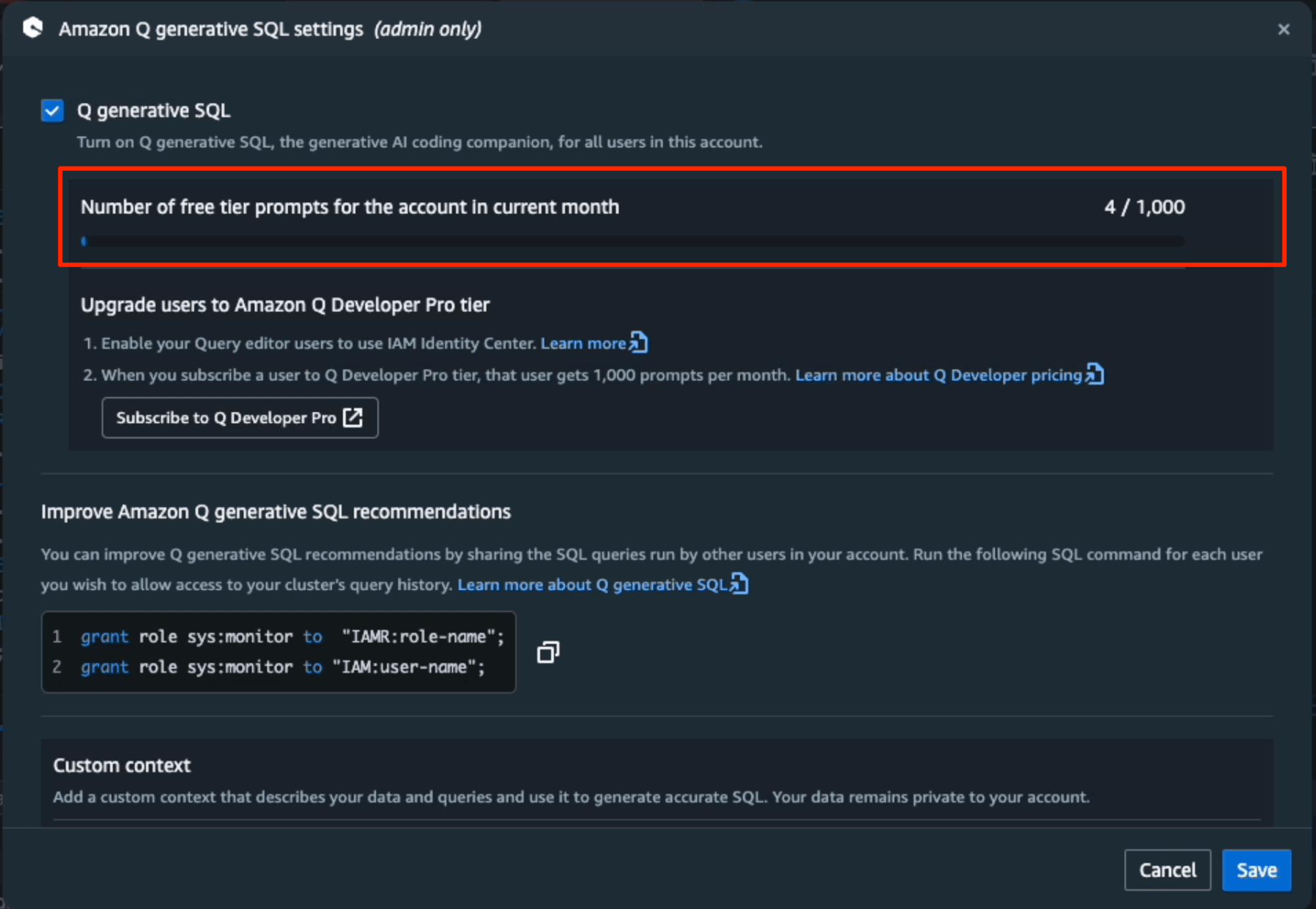
Amazon Q generative SQL for Amazon Redshift は、1ヶ月間1000プロンプトまで無料です。設定画面から何回SQLを実行したかを確認できます。今回は、4回実行したので、「4/1000」と表示が更新されています。限られた予算の中でも安心してご利用いただけます。
Amazon Redshift や Amazon Redshift Serverless をご利用の方は、これまでにないユーザー体験を、ぜひお試しください。
合わせて読みたい










